AI-Generated Audio Guides: What Museums Need to Know
Frequently Asked Questions
Do AI audio guides hallucinate incorrect information about artworks?
With well-orchestrated systems, hallucinations are effectively a solved problem. Good AI guide platforms ground every response in museum-provided data and clearly label when the AI draws on general knowledge beyond what the museum supplied. The risk comes from poorly built tools that let a general-purpose model freestyle.
How much do AI-generated audio guides cost compared to traditional audio guides?
AI audio guides sit between traditional hardware devices and basic BYOD solutions in price. There are no large upfront costs for scripting or recording. The ongoing cost comes from AI generation per interaction, which is falling rapidly. Most providers offer subscriptions, revenue share, or credit-based pricing.
Will an AI audio guide replace our curatorial voice?
The opposite. AI guide systems like Musa are built around preserving curatorial voice. Museums design the persona, tone, narrative structure, and per-stop instructions. The AI then speaks within those constraints in any language, rather than generating content from scratch.
What are the different types of AI audio guides available for museums?
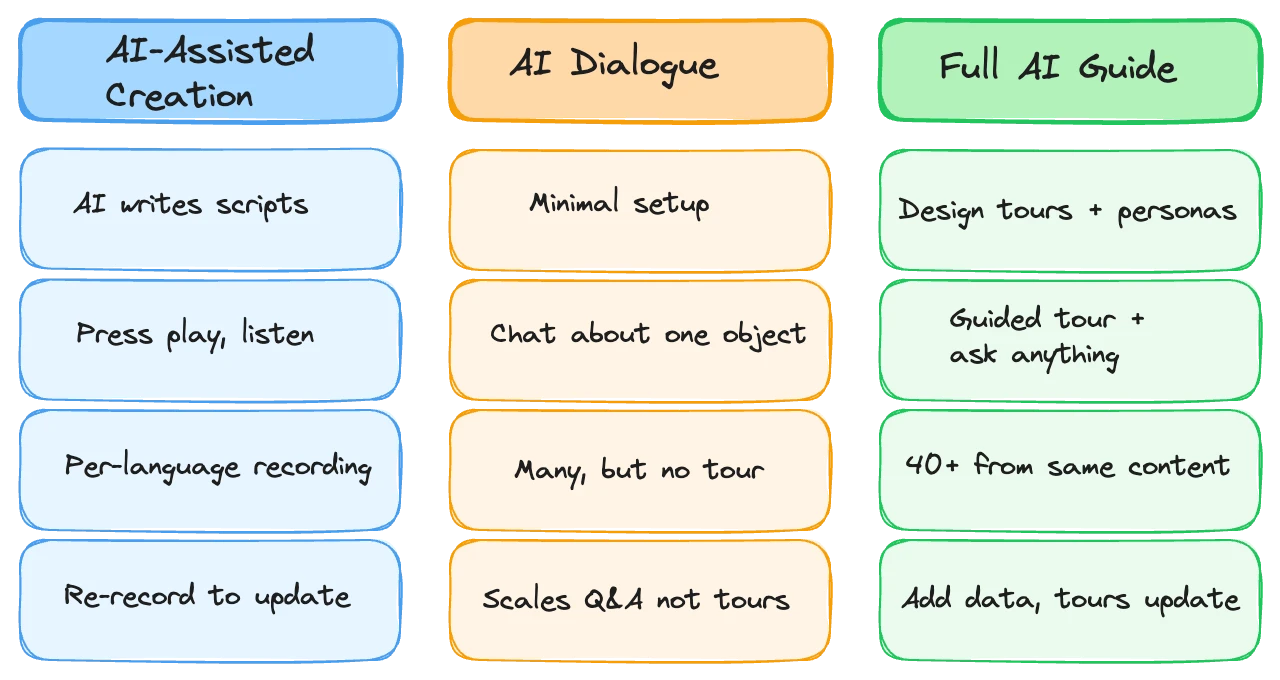
There are three categories: AI-assisted creation tools that help write scripts but deliver them traditionally, AI dialogue tools that let visitors chat with an AI about individual objects, and full AI guide platforms that handle both creation and real-time conversation across an entire tour.
Until recently, AI audio guides were not real. Products existed that called themselves AI-powered, but most were either traditional scripts written with ChatGPT or chatbots bolted onto a museum's collection page. Neither qualified as an actual AI-generated audio guide, one that creates and delivers a full visitor experience in real time.
That changed in the last eighteen months. Better language models, cheaper inference, and higher-quality text-to-speech have made it possible to build systems that generate a complete, narrated tour on the fly. These systems are grounded in a museum's own data, speak in a voice the museum controls, and work in dozens of languages simultaneously.
This article covers what works, what doesn't, what the real risks are, and how to evaluate these systems if you're considering one for your institution.
The three types of AI audio guides
Not all AI audio guides do the same thing. The label gets applied to three very different products, and the distinction matters.
AI-assisted creation. These tools use AI to help write scripts, translate text, or generate voiceover from finished scripts. The output is a traditional audio guide with fixed narration delivered linearly. The AI is in the production workflow, not in the visitor's hands. This is the most common category and the least disruptive. It speeds up content creation but doesn't change the visitor experience.
AI dialogue. These are chatbot-style products where a visitor can have a conversation with an AI about a specific artwork or exhibit. AskMona is the best-known example. The visitor asks questions, the AI responds, and the exchange continues until the visitor moves on. There's no curated tour structure, no guided journey through the space. Every interaction is a fresh back-and-forth about a single object. This works for deeply curious visitors who arrive with specific questions. For everyone else (people who want to be guided, told what to look at next, given context they didn't know to ask about) it falls flat. The burden is on the visitor to drive every interaction, and most people won't do that for an entire museum visit.
Full AI guide systems. These platforms handle both the creation and delivery side. A museum loads its data and designs tours: narrative arcs, stop sequences, character voices, tonal instructions. The AI then generates the tour in real time, responding to where the visitor is, what they've already heard, and what they ask along the way. The visitor gets a curated experience with the option to go deeper on anything. This is where things get interesting, and where the real evaluation questions come up. For a deeper look at how these systems work end to end, see our overview of AI audio guides.
Cost: what it actually looks like
The pricing conversation around AI audio guides is confused because people compare them against the wrong baselines.
Traditional hardware audio guides carry large upfront costs: scriptwriting, professional voice recording, translation into each language, device procurement, and ongoing maintenance. A full production for a mid-sized museum can run tens of thousands before a single visitor picks up a device. Then there are per-device costs, charging infrastructure, cleaning, repairs, and the staff time to manage the desk.
Basic BYOD (bring your own device) solutions, apps or web pages that deliver pre-recorded content on visitors' phones, are cheaper upfront but still require the same production investment in scripts and recordings. They just skip the hardware.
AI-generated guides sit between these two. The production cost is dramatically lower because there are no scripts to write per stop, no recording sessions to book, no per-language translation budgets. You load your content, design the tour, and the AI handles generation. The tradeoff is an ongoing cost per interaction. Every time a visitor uses the guide, AI inference runs, and that costs money. Those costs are falling fast (roughly halving every year), but they're real.
In practice, the total cost of ownership for an AI guide is competitive with traditional hardware guides right now, with far better output quality and none of the hardware logistics. Compared to basic BYOD solutions, AI guides cost slightly more but deliver a fundamentally different experience.
Business models vary. Some providers charge subscriptions. Others use revenue share, where the museum charges visitors and splits the revenue. Credit-based pricing ties cost directly to usage. Fixed monthly pricing is available too. The common thread is low or zero upfront investment, which matters for museums that have been burned by large capital expenditures on systems that underdelivered.
"But what about hallucinations?"
This is the question that comes up in every conversation with museum directors considering AI guides. It's the right question. A guide that makes up facts about your collection is worse than no guide at all.
The honest answer: with well-built, purpose-designed software, hallucinations are basically not a concern anymore.
That statement requires unpacking, because it's not universally true. A general-purpose chatbot like ChatGPT, pointed at a museum's collection, will hallucinate. It'll invent dates, attribute works to the wrong artist, and confidently state things that are wrong. That's because it's drawing on its training data (the entire internet) and filling gaps with plausible-sounding text.
A purpose-built AI guide system works differently. Every response is grounded in the museum's own data: catalog entries, wall texts, curator notes, research materials. The AI generates its narration from this closed knowledge base. When a visitor asks a question that goes beyond what the museum has provided, a good system will either say so explicitly ("Based on the museum's materials, I can tell you X, and for broader context, Y is generally understood to be the case") or stay within its boundaries.
The technical term is retrieval-augmented generation with guardrails. The practical result is that the AI speaks your content, not its imagination.
Zero risk? No. Adversarial users can try to push any system off course. But for normal visitor interactions, the questions people actually ask in museums, hallucination in a well-orchestrated system is a solved problem. We've seen this across thousands of real visitor sessions. Internal monitoring at the platform level can catch the rare edge case.
The real risk isn't hallucination from good software. It's hallucination from bad software, tools that wrap a general-purpose model in a museum skin without the underlying architecture to constrain it.
"We'll lose our curatorial voice"
This concern runs deeper than hallucinations for many museum professionals, and rightly so. A museum's interpretive voice is the product of years of scholarship, institutional identity, and deliberate curatorial choices. The fear is that an AI will flatten all of that into generic encyclopedia-speak.
With a naive implementation, that fear is justified. Hand your collection data to a default language model and ask it to narrate, and you'll get something that sounds like Wikipedia read aloud. Accurate, maybe. Yours? No.
But the best AI guide systems are specifically designed around this problem. The architecture isn't "dump data in, get narration out." It's layered.
Take Musa's approach as an example, because it's the one we know best. Museums don't just load data. They design characters, set tonal instructions, write per-stop narrative guidance, and define tour-level prompts that shape how the AI behaves throughout the entire visit. There are multiple layers of prompting: voice direction in the curated content itself, broader knowledge and behavioral instructions, stop-specific guidance, and tour-level narrative arcs. The result is more like being a film director than writing individual scripts. You set the vision, the constraints, the personality. The AI performs within those boundaries.
So a history museum can sound authoritative and measured while a children's museum sounds playful and encouraging, not because someone wrote different scripts, but because the underlying system is orchestrated differently. The curatorial voice isn't lost. It's amplified, because it now extends to every language, every visitor question, and every possible path through the collection, all within the guardrails the museum set.
Once that scaffolding is in place, adding new content is simple. A new acquisition, a temporary exhibition, an updated interpretation: add the data, and it immediately speaks in your voice. No new scripts, no re-recording.
The shift in mental model is significant. Stop thinking about writing an audio guide and start thinking about designing a tour guide. A person with deep knowledge of your collection, your interpretive philosophy, and your institutional voice, who happens to speak forty languages and never gets tired.
The current limitation: voice quality
Being honest about where things stand today, synthesized voices are good but not perfect. They're clear, intelligible, and natural enough that most visitors don't notice or mind. But they occasionally lack the warmth and subtle expressiveness of a skilled human narrator. A professional actor reading a script still sounds better in a direct comparison.
This gap is closing fast. The quality of text-to-speech has improved more in the last two years than in the previous decade. Models now handle emphasis, pacing, and emotional inflection with reasonable skill. Support for accents, speaking styles, and languages has become strong. We're talking native-quality output in over 40 languages, not just passable-if-you-squint machine translation voice.
Within a year or two, the distinction between AI-generated and human-recorded narration will be difficult for most listeners to detect. For museums evaluating now: voice quality is a real but rapidly shrinking limitation, and it's already far above the threshold where visitors find it distracting.
What to look for when evaluating
If you're considering an AI audio guide for your museum, here's what actually matters in the evaluation.
Grounding architecture. How does the system prevent hallucinations? Ask specifically about how it handles questions that go beyond your data. "We use GPT-5" is not an answer. The model is one component. The retrieval, grounding, and guardrail layers are what determine whether the output is trustworthy.
Curatorial control. Can you shape the voice, tone, and narrative structure? At how many levels? A system that only lets you upload data and pick a voice isn't giving you real control. You should be able to define behavior per stop, per tour, and at the institutional level.
Tour structure vs. single-object chat. Does the system deliver a guided experience, or is it just a question-answering interface? The difference matters enormously for visitor experience. Most people want to be guided. They want to know what to look at next, what the story is, why this room connects to the next one. A chatbot that only responds to questions puts the entire burden on the visitor.
Language quality. Ask for demos in languages you can evaluate. Not just English, French, and Spanish. Try smaller languages if they matter to your audience. "40 languages supported" means nothing if the output in Basque or Catalan sounds robotic. The best systems maintain native-quality speech patterns, including local idioms and natural phrasing, across their full language range.
Pricing transparency. Understand the per-interaction cost and how it scales. Ask about what happens when usage spikes during a blockbuster exhibition. Get clarity on whether you're paying for features or for usage. The best pricing models align the provider's incentives with yours: they do well when your guide is used, not when you're locked into a contract regardless of adoption.
Analytics depth. AI-generated guides produce conversational data that traditional guides never could. What questions are visitors asking at each stop? Where do they lose interest? What topics generate the most engagement? Which languages are most used? This data is valuable for exhibition planning and content development. Make sure the platform surfaces it in a useful way.
Comparing the main approaches
To make the evaluation concrete, here's how the three categories stack up on the dimensions that matter.
Content creation effort. AI-assisted tools reduce it but don't eliminate it. You still produce traditional content. Dialogue-only tools require minimal setup but deliver minimal structure. Full AI guide systems require upfront design work (characters, tours, instructions) but no per-stop scripting. The ongoing effort to add content is lowest with full systems because new data inherits existing voice and structure automatically.
Visitor experience. AI-assisted creation produces the same linear playback visitors already know. Dialogue-only tools offer deep engagement with individual objects but no journey. Full systems combine curated narrative flow with the ability to ask questions. Visitors can be passive (just listen), slightly engaged (follow inline suggestions), or fully interactive (ask anything).
Multilingual delivery. This is where AI guides pull dramatically ahead. A traditional guide needs separate recordings per language, each one budgeted, scheduled, and produced. An AI system generates every language from the same underlying content and instructions. Adding a language has near-zero marginal cost. For museums serving international audiences, this alone can justify the switch.
Scalability. Adding a temporary exhibition to a traditional guide means new scripts, new recordings, new QA. Adding it to a full AI system means loading the content and optionally adding stop-level instructions. The 80/20 principle applies: you get high-quality results very quickly, with the option to refine as much as you want.
Who this is for, and who should wait
AI-generated audio guides make the most sense for museums that want multilingual delivery without multiplying production costs, institutions replacing aging hardware fleets, collections that change regularly (temporary exhibitions, rotating displays), and sites that want visitor interaction beyond press-play-and-listen.
They're a harder sell if your museum already has a beloved, high-production-value audio guide with celebrity narration that visitors specifically seek out. In that case, an AI guide might work as a complement (handling languages and Q&A) rather than a replacement.
For small museums that have never offered any audio guide, the low upfront cost and usage-based pricing of AI systems make this newly accessible. You don't need a five-figure production budget to give visitors a guided experience anymore. That's a real shift in who can afford to offer audio interpretation.
Where this is heading
The trajectory is clear. Voice quality will reach human parity within a couple of years. Inference costs will continue to drop, making per-interaction pricing even more favorable. The systems that exist today will get better at understanding spatial context, adapting to visitor behavior in real time, and integrating with other museum systems.
The museums that start now will have an advantage, not because the technology will be obsolete later, but because the design work is cumulative. The tours you build, the personas you craft, the stop-level instructions you refine based on visitor data: all of that compounds. Museums that begin designing their AI guide today will have a more refined product in a year than those starting from scratch.